本文最后更新于 2026年4月23日 晚上
给标签表添加 status 和 sort 字段并对受其影响的所有接口进行修改
起因
我在做后台系统的时候发现分类列表中有状态和排序列,但是在标签中却没有
然后一看数据表 标签表里没有这两个字段
因为标签表是很前期的时候设计的
和后面设计的分类表没这么统一
这也是我在写这个项目中遇到的最大的设计缺陷
事到如今没办法了
只能改呗
你别看只是两个字段的事
他涉及到的接口(前台,后台)和类(实体类)这些可多了
工程亮巨大
改了我整整一天
需要修改的代码
和tag表有联系的类和表基本都要修改
首先就是实体类,其次是dto和vo
Tag
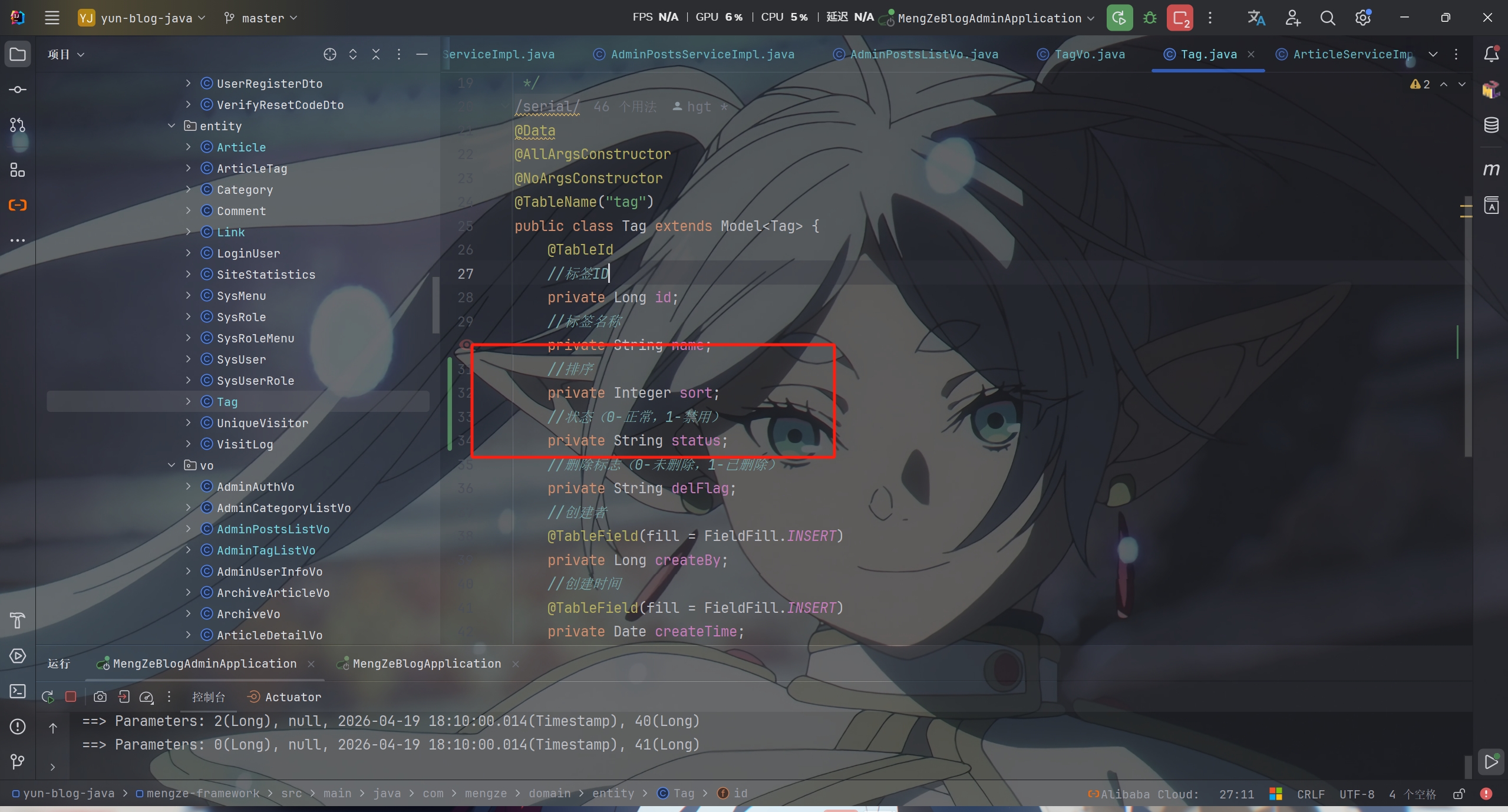
TagListDto
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel(description = "标签操作请求对象")
public class TagListDto {
@ApiModelProperty(value = "标签ID列表", required = true, example = "[1,2,3]")
private List<Long> ids;
@ApiModelProperty(value = "状态", example = "0")
private String status;
@ApiModelProperty(value = "关键字(用于模糊搜索标签名称)", example = "Vue")
private String keywords;
}
|
UpdateTagDto
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel(description = "更新标签请求对象")
public class UpdateTagDto {
@ApiModelProperty(value = "标签ID", required = true, example = "1")
private Long id;
@ApiModelProperty(value = "标签名称", required = true, example = "Java")
private String name;
@ApiModelProperty(value = "备注", example = "Java相关标签")
private String remark;
@ApiModelProperty(value = "排序", example = "1")
private Integer sort;
@ApiModelProperty(value = "状态(0-正常,1-禁用)", example = "0")
private String status;
}
|
AddTagDto
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
@Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel(description = "添加标签请求对象")
public class AddTagDto {
@ApiModelProperty(value = "标签名称", required = true, example = "Java")
private String name;
@ApiModelProperty(value = "备注", example = "Java相关标签")
private String remark;
@ApiModelProperty(value = "排序值", example = "0")
private Integer sort;
@ApiModelProperty(value = "状态(0-正常,1-禁用)", required = true, example = "0")
private String status;
}
|
AdminTagListVo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| @Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel(description = "标签响应对象")
public class AdminTagListVo
{
@ApiModelProperty(value = "标签ID")
private Long id;
@ApiModelProperty(value = "标签名")
private String name;
@ApiModelProperty(value = "状态(0-正常,1-禁用)")
private String status;
@ApiModelProperty(value = "排序")
private Integer sort;
@ApiModelProperty(value = "备注")
private String remark;
@ApiModelProperty(value = "文章数量")
private Integer articleCount;
@ApiModelProperty(value = "创建日期")
private Date createTime;
}
|
TagFormDetailVo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| @Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel(description = "后台标签表单详情响应对象")
public class TagFormDetailVo
{
@ApiModelProperty(value = "标签ID")
private Long id;
@ApiModelProperty(value = "标签名称")
private String name;
@ApiModelProperty(value = "备注")
private String remark;
@ApiModelProperty(value = "状态(0-正常,1-禁用)")
private String status;
@ApiModelProperty(value = "排序")
private String sort;
}
|
接下来就是用到tag的接口实现方法的修改
先是后台 AdminPostsServiceImpl 中的 postsList 和 getTagsByArticleId 方法
这里直接放源码了 省的我到时候想还原的时候一句一句来对
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
@Override
public ResponseResult postsList(Integer pageNum, Integer pageSize, PostsListDto postsListDto)
{
LambdaQueryWrapper<Article> queryWrapper = new LambdaQueryWrapper<>();
if (Objects.nonNull(postsListDto.getCategoryId()) && postsListDto.getCategoryId() > 0) {
queryWrapper.eq(Article::getCategoryId, postsListDto.getCategoryId());
}
if (StringUtils.hasText(postsListDto.getStatus())) {
queryWrapper.eq(Article::getStatus, postsListDto.getStatus());
}
if (StringUtils.hasText(postsListDto.getKeywords())) {
queryWrapper.and(wrapper -> wrapper
.like(Article::getTitle, postsListDto.getKeywords())
.or()
.like(Article::getSummary, postsListDto.getKeywords())
);
}
queryWrapper.orderByDesc(Article::getIsTop);
queryWrapper.orderByDesc(Article::getCreateTime);
Page<Article> page = new Page<>(pageNum, pageSize);
articleService.page(page, queryWrapper);
List<Article> articles = page.getRecords();
articles.forEach(article -> {
Category category = categoryService.getById(article.getCategoryId());
article.setCategoryName(category.getName());
article.setCategoryStatus(category.getStatus());
Integer viewCount = redisCache.getCacheMapValue(SystemConstants.ARTICLE_VIEW_COUNT, article.getId().toString());
article.setViewCount(viewCount.longValue());
});
List<AdminPostsListVo> postsListVos = BeanCopyUtils.copyBeanList(page.getRecords(), AdminPostsListVo.class);
postsListVos.forEach(postsListVo -> {
List<TagVo> tags = getTagsByArticleId(postsListVo.getId());
postsListVo.setTags(tags);
});
PageVo pageVo = new PageVo(postsListVos, page.getTotal());
return ResponseResult.okResult(pageVo);
}
private List<TagVo> getTagsByArticleId(Long articleId)
{
LambdaQueryWrapper<ArticleTag> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(ArticleTag::getArticleId, articleId);
List<ArticleTag> articleTags = articleTagMapper.selectList(queryWrapper);
List<Long> tagIds = articleTags.stream()
.map(ArticleTag::getTagId)
.collect(Collectors.toList());
if (tagIds.isEmpty()) {
return List.of();
}
List<Tag> tags = tagService.listByIds(tagIds);
return tags.stream()
.map(tag -> {
TagVo tagVo = new TagVo();
tagVo.setId(tag.getId());
tagVo.setName(tag.getName());
tagVo.setStatus(tag.getStatus());
tagVo.setCreateTime(tag.getCreateTime());
LambdaQueryWrapper<ArticleTag> countWrapper = new LambdaQueryWrapper<>();
countWrapper.eq(ArticleTag::getTagId, tag.getId());
Long count = articleTagMapper.selectCount(countWrapper);
tagVo.setArticleCount(count.intValue());
return tagVo;
})
.collect(Collectors.toList());
}
|
然后就是 AdminTagServiceImpl 里的 tagList 和 getTagOptions 方法
这里给以后可能会懵逼的自己解释一下
为什么 updateTag 不用像 updateCategory 一样 检查是否将分类状态从正常改为禁用 然后提示有多少篇文章收到影响了
这是因为分类和文章是一对一的关系
而标签和文章是一对多的关系
在前几篇文章对分类的修改中
将分类禁用后与这个分类相关的文章应该是不能在前台显示的 但是后台应该显示
所以要检查并提示用户这个信息
但是标签不一样
一对多的情况下
后台禁用某个标签
前台在这个文章的标签信息和标签列表页面里不显示这个标签就行了
但是文章还是可以显示的
这也跟后台写博客中标签的可选性相关联上了
这种操作是直觉性的
而分类禁用后不给出提示
用户就很容易忽视分类和文章的一对一关系
用户去前台看会发现分类没了文章怎么也没了
这样就会很迷惑
综上:updateTag 和 updateCategory 两个方法的区别原因就是这样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
|
@Override
public ResponseResult tagList(Integer pageNum, Integer pageSize, TagListDto tagListDto)
{
LambdaQueryWrapper<Tag> tagQueryWrapper = new LambdaQueryWrapper<>();
if (StringUtils.hasText(tagListDto.getKeywords())) {
tagQueryWrapper.like(Tag::getName, tagListDto.getKeywords());
}
tagQueryWrapper.eq(Tag::getDelFlag, SystemConstants.NOT_DELETED);
if (StringUtils.hasText(tagListDto.getStatus())) {
tagQueryWrapper.eq(Tag::getStatus, tagListDto.getStatus());
}
tagQueryWrapper.orderByDesc(Tag::getCreateTime);
Page<Tag> page = new Page<>(pageNum, pageSize);
tagService.page(page, tagQueryWrapper);
LambdaQueryWrapper<Article> articleQueryWrapper = new LambdaQueryWrapper<>();
articleQueryWrapper.eq(Article::getDelFlag, SystemConstants.NOT_DELETED)
.select(Article::getId);
List<Article> validArticles = articleService.list(articleQueryWrapper);
Set<Long> validArticleIds = validArticles.stream()
.map(Article::getId)
.collect(Collectors.toSet());
List<ArticleTag> articleTagList = articleTagMapper.selectList(null);
Map<Long, Long> tagArticleCountMap = articleTagList.stream()
.filter(articleTag -> validArticleIds.contains(articleTag.getArticleId()))
.collect(Collectors.groupingBy(ArticleTag::getTagId, Collectors.counting()));
List<AdminTagListVo> tagListVos = page.getRecords().stream()
.map(tag -> {
AdminTagListVo tagListVo = BeanCopyUtils.copyBean(tag, AdminTagListVo.class);
tagListVo.setArticleCount(tagArticleCountMap.getOrDefault(tag.getId(), 0L).intValue());
return tagListVo;
})
.collect(Collectors.toList());
PageVo pageVo = new PageVo(tagListVos, page.getTotal());
return ResponseResult.okResult(pageVo);
}
@Override
public ResponseResult getTagOptions()
{
LambdaQueryWrapper<Tag> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(Tag::getDelFlag, SystemConstants.NOT_DELETED)
.eq(Tag::getStatus, SystemConstants.STATUS_NORMAL)
.orderByDesc(Tag::getId);
List<Tag> tags = tagService.list(queryWrapper);
List<TagOptionVo> tagOptionVos = BeanCopyUtils.copyBeanList(tags, TagOptionVo.class);
return ResponseResult.okResult(tagOptionVos);
}
|
前台接口 ArticleServiceImpl 中 articleList 和 fillArticleListTags 和 fillArticleDetailTags 方法
其实主要是 fillArticleListTags 方法
因为前面已经把 articleList 中对 文章列表添加标签数据 和 为文章详情添加标签数据 的代码提取出来封装成 fillArticleListTags 和 fillArticleDetailTags 方法了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
@Override
public ResponseResult articleList(Integer pageNum, Integer pageSize)
{
LambdaQueryWrapper<Article> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.inSql(Article::getCategoryId,
"SELECT id FROM category WHERE status = '0' AND del_flag = '0'");
lambdaQueryWrapper.eq(Article::getStatus, SystemConstants.ARTICLE_STATUS_NORMAL);
lambdaQueryWrapper.orderByDesc(Article::getIsTop);
lambdaQueryWrapper.orderByDesc(Article::getCreateTime);
Page<Article> page = new Page<>(pageNum, pageSize);
page(page, lambdaQueryWrapper);
List<Article> articles = page.getRecords();
articles.forEach(article -> {
article.setCategoryName(categoryService.getById(article.getCategoryId()).getName());
Integer viewCount = redisCache.getCacheMapValue(SystemConstants.ARTICLE_VIEW_COUNT, article.getId().toString());
article.setViewCount(viewCount.longValue());
});
List<ArticleListVo> articleListVos = BeanCopyUtils.copyBeanList(page.getRecords(), ArticleListVo.class);
fillArticleListTags(articleListVos);
PageVo pageVo = new PageVo(articleListVos, page.getTotal());
return ResponseResult.okResult(pageVo);
}
private void fillArticleListTags(List<ArticleListVo> articleListVos)
{
List<Long> articleIds = articleListVos.stream()
.map(ArticleListVo::getId)
.collect(Collectors.toList());
LambdaQueryWrapper<ArticleTag> articleTagWrapper = new LambdaQueryWrapper<>();
articleTagWrapper.in(ArticleTag::getArticleId, articleIds);
List<ArticleTag> articleTagList = articleTagMapper.selectList(articleTagWrapper);
List<Long> tagIds = articleTagList.stream()
.map(ArticleTag::getTagId)
.distinct()
.collect(Collectors.toList());
LambdaQueryWrapper<Tag> tagWrapper = new LambdaQueryWrapper<>();
tagWrapper.in(Tag::getId, tagIds)
.eq(Tag::getStatus, SystemConstants.STATUS_NORMAL)
.eq(Tag::getDelFlag, SystemConstants.NOT_DELETED);
List<Tag> tags = tagMapper.selectList(tagWrapper);
Map<Long, TagVo> tagVoMap = tags.stream()
.collect(Collectors.toMap(
Tag::getId,
tag -> BeanCopyUtils.copyBean(tag, TagVo.class)
));
Map<Long, List<TagVo>> articleTagMap = articleTagList.stream()
.filter(at -> tagVoMap.containsKey(at.getTagId()))
.collect(Collectors.groupingBy(
ArticleTag::getArticleId,
Collectors.mapping(
at -> BeanCopyUtils.copyBean(tagVoMap.get(at.getTagId()), TagVo.class),
Collectors.toList()
)
));
articleListVos.forEach(article ->
article.setTags(articleTagMap.getOrDefault(article.getId(), List.of()))
);
}
private void fillArticleDetailTags(ArticleDetailVo articleDetailVo)
{
LambdaQueryWrapper<ArticleTag> articleTagWrapper = new LambdaQueryWrapper<>();
articleTagWrapper.eq(ArticleTag::getArticleId, articleDetailVo.getId());
List<ArticleTag> articleTagList = articleTagMapper.selectList(articleTagWrapper);
List<Long> tagIds = articleTagList.stream()
.map(ArticleTag::getTagId)
.collect(Collectors.toList());
LambdaQueryWrapper<Tag> tagWrapper = new LambdaQueryWrapper<>();
tagWrapper.in(Tag::getId, tagIds)
.eq(Tag::getStatus, SystemConstants.STATUS_NORMAL)
.eq(Tag::getDelFlag, SystemConstants.NOT_DELETED);
List<Tag> tags = tagMapper.selectList(tagWrapper);
List<TagVo> tagVos = BeanCopyUtils.copyBeanList(tags, TagVo.class);
articleDetailVo.setTags(tagVos);
}
|
还有就是 AdminPostsServiceImpl 里的 postsList 和 getTagsByArticleId 方法
其实这是对文章管理里的升级
因为前面修改之后在文章管理页面里很难看到 分类 和 标签 列里分类和标签的状态
后端要多传两个字段 categoryStatus status(标签) 给前端
然后前端根据分类和标签的状态对分类和标签做出提示
由于也涉及到标签的修改
在这里也改了
后面再对 获取文章列表接口进行更新
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
@Override
public ResponseResult postsList(Integer pageNum, Integer pageSize, PostsListDto postsListDto)
{
LambdaQueryWrapper<Article> queryWrapper = new LambdaQueryWrapper<>();
if (Objects.nonNull(postsListDto.getCategoryId()) && postsListDto.getCategoryId() > 0) {
queryWrapper.eq(Article::getCategoryId, postsListDto.getCategoryId());
}
if (StringUtils.hasText(postsListDto.getStatus())) {
queryWrapper.eq(Article::getStatus, postsListDto.getStatus());
}
if (StringUtils.hasText(postsListDto.getKeywords())) {
queryWrapper.and(wrapper -> wrapper
.like(Article::getTitle, postsListDto.getKeywords())
.or()
.like(Article::getSummary, postsListDto.getKeywords())
);
}
queryWrapper.orderByDesc(Article::getIsTop);
queryWrapper.orderByDesc(Article::getCreateTime);
Page<Article> page = new Page<>(pageNum, pageSize);
articleService.page(page, queryWrapper);
List<Article> articles = page.getRecords();
articles.forEach(article -> {
Category category = categoryService.getById(article.getCategoryId());
article.setCategoryName(category.getName());
article.setCategoryStatus(category.getStatus());
Integer viewCount = redisCache.getCacheMapValue(SystemConstants.ARTICLE_VIEW_COUNT, article.getId().toString());
article.setViewCount(viewCount.longValue());
});
List<AdminPostsListVo> postsListVos = BeanCopyUtils.copyBeanList(page.getRecords(), AdminPostsListVo.class);
postsListVos.forEach(postsListVo -> {
List<TagVo> tags = getTagsByArticleId(postsListVo.getId());
postsListVo.setTags(tags);
});
PageVo pageVo = new PageVo(postsListVos, page.getTotal());
return ResponseResult.okResult(pageVo);
}
private List<TagVo> getTagsByArticleId(Long articleId)
{
LambdaQueryWrapper<ArticleTag> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(ArticleTag::getArticleId, articleId);
List<ArticleTag> articleTags = articleTagMapper.selectList(queryWrapper);
List<Long> tagIds = articleTags.stream()
.map(ArticleTag::getTagId)
.collect(Collectors.toList());
if (tagIds.isEmpty()) {
return List.of();
}
List<Tag> tags = tagService.listByIds(tagIds);
return tags.stream()
.map(tag -> {
TagVo tagVo = new TagVo();
tagVo.setId(tag.getId());
tagVo.setName(tag.getName());
tagVo.setStatus(tag.getStatus());
tagVo.setCreateTime(tag.getCreateTime());
LambdaQueryWrapper<ArticleTag> countWrapper = new LambdaQueryWrapper<>();
countWrapper.eq(ArticleTag::getTagId, tag.getId());
Long count = articleTagMapper.selectCount(countWrapper);
tagVo.setArticleCount(count.intValue());
return tagVo;
})
.collect(Collectors.toList());
}
|
最后就是前台 TagServiceImpl 中的 getTagList 方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
@Override
public ResponseResult getTagList()
{
LambdaQueryWrapper<Article> articleWrapper = new LambdaQueryWrapper<>();
articleWrapper.inSql(Article::getCategoryId,
"SELECT id FROM category WHERE status = '0' AND del_flag = '0'")
.eq(Article::getStatus, SystemConstants.ARTICLE_STATUS_NORMAL);
List<Article> articleList = articleService.list(articleWrapper);
Set<Long> articleIds = articleList.stream()
.map(Article::getId)
.collect(Collectors.toSet());
LambdaQueryWrapper<ArticleTag> articleTagWrapper = new LambdaQueryWrapper<>();
if (!articleIds.isEmpty()) {
articleTagWrapper.in(ArticleTag::getArticleId, articleIds);
} else {
articleTagWrapper.eq(ArticleTag::getArticleId, -1L);
}
List<ArticleTag> articleTagList = articleTagMapper.selectList(articleTagWrapper);
Set<Long> tagIds = articleTagList.stream()
.map(ArticleTag::getTagId)
.collect(Collectors.toSet());
Map<Long, Long> tagArticleCountMap = articleTagList.stream()
.collect(Collectors.groupingBy(ArticleTag::getTagId, Collectors.counting()));
LambdaQueryWrapper<Tag> tagWrapper = new LambdaQueryWrapper<>();
if (!tagIds.isEmpty()) {
tagWrapper.in(Tag::getId, tagIds);
} else {
tagWrapper.eq(Tag::getId, -1L);
}
tagWrapper.eq(Tag::getDelFlag, SystemConstants.NOT_DELETED)
.eq(Tag::getStatus, SystemConstants.STATUS_NORMAL);
List<Tag> tagList = list(tagWrapper);
List<TagVo> tagVoList = tagList.stream()
.map(tag -> {
TagVo tagVo = BeanCopyUtils.copyBean(tag, TagVo.class);
tagVo.setArticleCount(tagArticleCountMap.getOrDefault(tag.getId(), 0L).intValue());
return tagVo;
})
.collect(Collectors.toList());
return ResponseResult.okResult(tagVoList);
}
|
至此所有的修改都已完成 修改前端之后经过测试都没问题了
其实后面还有 友链表 的升级
但是由于友链表的后台相关接口都还没开发到 这个修改只影响到前台接口
下篇就是对这些接口进行修改和排查
现在升级完了不会影响这么多代码
在此告诫大家一定要先把数据表设计好了再开写
这改的我都要哭了

PS:该系列只做为作者学习开发项目做的笔记用
不一定符合读者来学习,仅供参考
预告
后续会记录博客的开发过程
每次学习会做一份笔记来进行发表
“一花一世界,一叶一菩提”
版权所有 © 2026 云梦泽
欢迎访问我的个人网站:https://hgt12.github.io/